We Need to Talk About Observation
(Note: Every buzz-and-nonbuzz word of this post was painstakingly conceived and typed by hand using a real-ass keyboard and a real-ass text editor running on my personal computer in my home office outside Cleveland, Ohio. No GPUs were harmed in the making of this film.)
TL;DR
For the Impatient of Spirit among you: Apple has effectively deprecated the reigning paradigm of the ObservableObject protocol and @Published properties observed via the Combine framework, but they’ve only partially provided its replacement via the @Observable macro and the withObservationTracking free function. The gaps between the old way and the new way are worth careful consideration.
Out with the old…
Since the advent first of the React framework and then later other similar projects—SwiftUI, Jetpack Compose, etc.—the peppiest and most responsive apps these days are written as thin layers of declarative UI code that spontaneously react to changes in thick layers of object-oriented code. Those latter objects are sometimes called “view models” or “flow coordinators” or whatever you wish to call them. Naming aside, the reactive paradigm on Apple platforms has been reified by SwiftUI. It has usurped UIKit/AppKit as the dominant framework for new UI development.
What I find most exciting about SwiftUI isn’t just the fact that it’s declarative. What’s most exciting is the other half of my codebase. I’m excited about all the stuff that isn’t SwiftUI. Business logic. View models. UserProviderManagerHamburgerHelper. Files that only have import Foundation at the top and nothing else. That stuff gets written entirely differently in a pure SwiftUI world, relative to how it was written for UIKit/AppKit. In the relatively-before-times, in the kinda-sorta-long-long-ago, there were DataSources and Delegates, IBOutlets and IBActions. Stuff worked like an old telephone switchboard: somebody had to plug the dataSource cable into the SomethingSomethingDataSource jack in a wall of such holes. If anything worked, its because a giant tangle of loosely coupled, weakly-referenced properties got wired up just-in-time.
Ignoring for now, because we will discuss them below, the @Observable macro and the Observation framework, contemporary application code that I regard as Pure and Faultless is this: a thin shell of incredibly dumb UI code wrapping a core of intelligent business logic factored into a constellation of focused, domain-specific objects:
@MainActor final class MyModel: ObservableObject {
@Published var stuff = Stuff.initialStuff()
@Published var error: PresentableError?
var disableNextButton: Bool { /* hard stuff */ }
func next() { /* complex stuff */ }
}
struct MyView: View {
@StateObject var model = MyModel()
var body: some View {
StuffEditor(stuff: $model.stuff)
Button("Next") {
model.next()
}.disabled(model.disableNextButton)
}
}
I’ll select one thing to highlight in the above sample code: notice that the “Next” button action is just model.next(). There’s no need to guard model.stuff.isValidAndEverything else { return }, because that’s handled by .disabled(model.disableNextButton). My view is exceptionally easy to discard and rewrite for Liquid Glass without having to rewrite and retest any business logic. This kind of code is easy to write and maintain, and is wine to you, wine and comfort, if you care about shipping new stuff fast and good and cheap, all three.
I want to show one more example before I get into how Apple has taken an axe to major portions of this approach.
It’s not just declarative UI that has been enabled by the reactive pattern. It’s also the behaviors that spring up between non-UI objects. Once an app reaches a sufficient level of real-world complexity, your app will have all kinds of important relationships:
// View relying on model:
view <---- object
// Object relying on delegate/data-source:
object <---- object
// One-to-many observations:
object ----> [object, object, object, ...]
It’s that third one that has been accelerated in recent years by the Combine framework, the ObservableObject protocol, and the @Published property wrapper.
I’ve written and reviewed no shortage of code that looks a lot like this contrived beauty (which I have shorn of Swift’s concurrency isolation grievances for brevity):
@MainActor final class UserCoordinator: ObservableObject {
@Published private(set) user: User?
}
@MainActor final class SyncEngine: ObservableObject {
@Published private(set) var status: Status = .idle
private var cancellables: Set<AnyCancellable> = []
func observe(_ coordinator: UserCoordinator) {
coordinator.$user
.removeDuplicates()
.sink { [weak self] user in
self?.restartOrCancelSync(newUser: user)
}
.store(in: &subscriptions)
}
}
I was able to write the above without bothering to switch to Xcode from my preferred Markdown editor to get the syntax correct. It’s an easy pattern to reproduce, and it works alongside SwiftUI in a quietly supportive fashion. Need a view that displays the sync progress? Just pass a reference to SyncEngine to your view and connect a ProgressView to that status property, bada-bing. Important: you do not need a View in order for the SyncEngine to do its job. The SyncEngine is fully capable of subscribing to changes to the user property of the UserCoordinator and programmatically, spontaneously respond to the activity of the UserCoordinator, without either the UI or the UserCoordinator needing any awareness of this behavior.
It just works.
But Apple has taken an axe to all that.
…and in with the new
Combine has been softly deprecated since structured concurrency was debuted, more softly in iOS 13 when AsyncSequence was released, but even more so over the subsequent years with improvements to structured concurrency and the introduction of the @Observable macro in iOS 17. It is now possible to subscribe to long-running streams of elements emitted asynchronously using structured concurrency:
func subscribe<S>(
to sequence: S
) async where S: AsyncSequence, S.Element = User?, S.Failure = Never {
for await user in sequence {
restartOrCancelSync(newUser: user)
}
}
The @Observable macro has usurped ObservableObject as the de rigeur way to write a “view model” type of object:
@MainActor @Observable final class MyModel {
var stuff = Stuff.initialStuff()
var error: PresentableError?
var disableNextButton: Bool { /* hard stuff */ }
func next() { /* complex stuff */ }
}
struct MyView: View {
@State var model = MyModel()
var body: some View {
StuffEditor(stuff: $model.stuff)
Button("Next") {
model.next()
}.disabled(model.disableNextButton)
}
}
There are a ton of problems with that code, as-written. It might compile, but it wouldn’t pass code review if you ran it past me at work. But before I get to that, let’s talk about what’s good about it, because I do appreciate the ways in which this new stuff is a step forward:
- Breathing room: - You don’t need a ton of
@Publishedproperty wrappers. Observability is opt-out, not opt-in. Also (not pictured here), if your view doesn’t need editing capability, you can use a plain-oldletproperty without the@State. - Optimization: - Only the properties of an @Observable object that are accessed by your little slice of the view hierarchy are invalidated during a UI update. The old thing was a big, blunt hammer that incurred too many unnecessary redraws.
- Nesting - If you want to refactor MyModel to be a composition of several smaller @Observable objects, you can do that without having to rewrite your view hierarchy. This is huge.
But there are the problems with the code as I’ve written it above. Exploring those problems, and the paucity of their solutions, will shed light on the shortcomings in the new status quo:
-
Needless object recreation. - See that line where the
@Stateproperty replaced the old@StateObject? That’s more than cosmetic. StateObject memoized its initialization via an escaping autoclosure over the default value, so that over the view’s lifetime on-screen, only one instance of the model would have been instantiated. The State wrapper offers no such feature. Anything that causes the MyView struct (not the on-screen view it represents, the struct itself, easy to misunderstand) to be recomputed by its ancestors—which is astonishingly easy in any real-world application—will discard the old instance and create a new one. I’ve seen this happen a lot with form validation and keyboards. At worst, a view model getsr-e-c-r-e-a-t-e-don every keypress. If you’ve got anything expensive happening inside that view model’sinitmethod, buddy: watch out. -
No streamlined way to avoid object recreation. - If you want to avoid that needless recreation, and bring back that old StateObject behavior, Apple’s recommendation has been—and still is even in OS 26!—to do the following tedious
onAppearmodifier dance:
struct MyView: View {
@State private var model: Model?
var body: some View {
content.onAppear {
if model == nil {
model = Model()
}
}
}
@ViewBuilder var content: some View {
if let model {
MyActualView(model: $model)
} else {
Color.clear
}
}
That’s very difficult to generalize. There ain’t no way to write a property wrapper to do it. At best, you can write a reusable generic View that takes two blocks: one that instantiates the state and another that provides the view. However you solve it, it is tedious and annoying to write code like this. But it’s totally necessary if your Model class, unlike my example above, requires any initialization parameters—which it should, because you ought not to be using networking and database singletons.
But I have a bigger problem with this new paradigm, and it isn’t visible from a UI code sample.
Where did you go, programmatic observation?
Remember I wrote this above:
What’s most exciting is the other half of my codebase.
In a sufficiently complex, real-world application, the thin layers of SwiftUI code are only half the picture. There is usually, if you’re separating concerns, a constellation of domain-specific objects that perform duties that aren’t user-visible or aren’t visible right away. These duties often require establishing one-to-one or one-to-many observation from one object to other objects that it knows nothing about. In the world of the ObservableObject protocol and @Published properties, the exact same mechanism that powers the relationship between an object and a view also powers the relationship between an object and another object. But with the @Observable macro, the object-to-object relationship is different. Much different.
In my opinion, it’s undercooked.
iOS 17: withObservationTracking comes withGreatResponsibility
In iOS 17 the withObservationTracking free function is the only way for something to subscribe to changes to an @Observable macro’ed object:
func withObservationTracking<T>(
_ apply: () -> T,
onChange: @autoclosure () -> () -> Void
) -> T
It’s behavior may really surprise you, if your previous mental model has been shaped, like mine has, by Combine. Let’s break it down:
withObservationTrackingthis is a synchronous function without any Swift concurrency isolation sugar except that which you get by default for nonisolated, synchronous functions.applyThis is a synchronous function parameter that is invoked exactly once, immediately. The value returned from this function is theTreturned from withObservationTracking. You don’t actually have to return anything butVoidif you don’t need a return value. But you must access properties of your @Observed object(s) insideapply. Only the properties that are accessed will be tracked for future changes. It is sufficient just toprint(myModel.value)inside theapplyif that’s all you need. It is headscratchingly difficult to grok how to correctly implement anapplybody if you’re bringing a Combine mental model to the table.onChangeThis is a synchronous, escaping, autoclosed function. It will be called either once or zero times, and no more. It is not like a Combinesink, which is called upon every emitted value. It is called either zero times (if the observed object never changes the properties you accessed inapply) or exactly once (if one or more of those properties change in the future).
If you want to have sustained, ongoing observation of all future changes, then you have to add a recursive tail-call to the onChange that (probably reëntrantly) calls withObservationTracking again.
Returning to my example above of a SyncEngine observing a UserCoordinator, let’s look at how this would work with @Observable:
@MainActor @Observable final class UserCoordinator {
private(set) user: User?
}
@MainActor @Observable final class SyncEngine {
private(set) var status: Status = .idle
func observe(_ coordinator: UserCoordinator) {
withObservationTracking {
restartOrCancelSync(newUser: coordinator.user)
} onChange: { [weak self, weak coordinator] in
// recursive tail-call:
guard let self, let coordinator else { return }
self.observe(coordinator)
}
}
}
What’s missing from that picture?
-
Discoverability - It isn’t easy to understand how to use this function. It’s a free function, not a
$memberof the object you’re trying to observe, which makes it harder to discover. -
Cancellation - How do I cancel my observation? How many times will this run? With Combine, you were given an explicit
AnyCancellablefrom thesinkmethod. Your subscription lived until you either calledcancel()or discarded the object. There’s no such thing returned here. You might wonder then if you’re supposed to use structured concurrency,Task.cancel(), but that’s not it, either. There’s no interplay with structured concurrency here. The answer is this: “cancellation” means “don’t do a recursive tail-call”, but that isn’t the same thing as cancellation. Your subscription, so-called, is always a one-shot, and it never resolves until the next time theonChangehandler fires, which might never happen. If you don’t want to observe changes anymore, you have to do something like (a) rely on[weak self]to cause your object to disappear, and/or (b) add aprivate var dontObserveAnymore: Boolproperty to your object and set that dirty bit totrueto prevent future recursive tail-calls via, like, aguardor something. It’s entirely up to you. There is no established pattern, and definitely no off-the-shelf API guiding your hand.
It all feels phoned-in, hardly the replacement for the opinionated, curated set of public APIs offered by the Combine framework.
iOS 26: Observations struct
New in iOS/macOS/etc 26 (technically new in Swift 6.2, but since the runtime no longer gets embedded in binaries, it’s unavailable prior to OS 26), there is now the Observations struct. Don’t confuse it with the Observation package to which it belongs (don’t miss that dangling, plural ess…)
Observations is an Apple-provided way for one object to subscribe to long-running changes to some other, @Observable-macro’ed object. It is written to use the AsyncSequence protocol. Despite the fact that withObservationTracking was released in OS 17, Observations has not been back-ported and requires OS 26.
Usage of Observations is like any other AsyncSequence. You use the for in await keywords. Here’s my SyncEngine example, rewritten to use Observations:
@MainActor @Observable final class UserCoordinator {
private(set) user: User?
}
@MainActor @Observable final class SyncEngine {
private(set) var status: Status = .idle
func observe(_ coordinator: UserCoordinator) async {
let obs = Observations.untilFinished { [weak coordinator] in
guard let coordinator else { return .finish }
return coordinator.user
}
for await user in obs {
restartOrCancelSync(newUser: user)
}
}
}
This is a mix of steps forward and steps backward. I’ll start with the positive:
The Positive
-
Structured Concurrency - The new API is written with structured concurrency in mind. The closure passed to
Observation.untilFinished(as well as to the unboundedinitalternative) is annotated with@isolated(any)and@_inheritActorContextand other goodies that make it play nicely even in Swift 6 language mode. You can stop your stream from emitting subsequent values by either throwing an error or returning.finish. More on the topic of cancellation and stream-stopping below, it’s not all rosy. -
Generics - The struct is generic over both the elements it produces and the errors it throws. This lends itself to terse, idiomatic Swift code. The
withObservationTrackingfunction didn’t allow for throwing errors at all.
But there are shortcomings with this new API, some of which are particularly gnarly to resolve.
The Gnarly
The gnarly bits are really just one, big, gnarly problem with multiple facets: it is hard to reason about the lifetime of the Observations async sequence and the lifetimes of the objects involved. But I’ll try to separate out those problems here because I like bulleted lists.
- Cancellation - It still isn’t as clear, compared to Combine’s
AnyCancellable, how you’re supposed to cancel an Observations struct. There’s no obvious visible API surface for doing so. You might wonder if Task cancellation is the way. You would be correct. To implement cancellation you need to wrap the entire thing in a Task, store that task in an instance variable, and determine key points in the lifecycle of your object to cancel that task:
@MainActor @Observable final class SyncEngine {
private(set) var status: Status = .idle
private var userObservation: Task<Void, any Error>?
deinit {
userObservation?.cancel()
}
func observe(_ coordinator: UserCoordinator) async {
userObservation = Task { [weak self] in
let coordinator = self?.coordinator
let obs = Observations.untilFinished { [weak coordinator] in
guard let coordinator else { return .finish }
return coordinator.user
}
for await user in obs {
if self == nil {
throw CancellationError()
}
self?.restartOrCancelSync(newUser: user)
}
}
}
}
There are problems with the above code, though, and I don’t recommend doing things exactly that way.
-
Object lifetimes - It is important that your
Taskand yourObservationsstructs weakly-capture bothselfand whatever object you’re trying to observe. But it’s still easy to get it wrong. It just as hard here as it was in the “old” days of Objective-C block capture semantics. A variable captured weakly in an outer scope can still live longer than you wish. See how I have that statement inside the Tasklet coordinator = self?.coordinator? That local variablecoordinatoris going to remain in memory for as long as the Task body has lexical scope, and that is as long as theawaitdown below is still waiting on the next value, which is potentially forever if you’ve thus created a retain cycle between the Task that is sustaining the lifetime of the coordinator and the coordinator, never producing another value, sustaining the Task. -
Actor isolation hassles with cancellation - That
deinitmethod isn’t isolated to the Main Actor, not yet. You can’t access a mutablevarproperty from the deinit. You would need to wrap that property in some kind of synchronization box, like a Mutex, which comes with its own kinds of hassles and boilerplate.
Side note: the source code for Observations is open to public view. If you squint hard enough, you can figure out that it’s basically a gigantic, V-Ger like edifice around withObservationTracking with recursive tail-calls handled as a combination of state machinery and the AsyncSequence protocol. I find it simultaneously (concurrently?) both nifty and somewhat deflating that Apple’s solution to programmatic observation of @Observable macro objects is still propped up by the ho-hum withObservationTracking free function.
Alas.
What We’ve Lost
It’s worth comparing the Observations example above (the version where I wrapped it in a Task and manually managed cancellation inside a deinit method) versus the exact same equivalent behavior implemented via Combine observation of a @Published property:
private var cancellables: Set<AnyCancellable> = []
func observe(_ coordinator: UserCoordinator) {
coordinator.$user
.sink { [weak self] user in
self?.restartOrCancelSync(newUser: user)
}
.store(in: &subscriptions)
}
}
Look how much more succinct that is! And how little it relies on needing to grok whatever is going on with an enclosing structured concurrency Task from which observe(_:) happens to be called.
With Combine (a) you don’t have to override deinit, (b) you don’t have to specialize the cancellables property with generics which means (c) you can store multiple subscriptions in a single property with ease, (d) you don’t have to remember to weakly-reference the object being observed because it’s done for you, (e) AnyCancellable does the minimum-viable thing for you automatically by cancelling itself when destroyed, which (f) in the majority of use cases is more than good enough to limit Combine observation streams to the correct duration.
Further recommendations
Even despite all my qualms, I remain convinced that the @Observable macro is the right path forward, both for Apple and their third-party developer community. I really appreciate the ways that it works with SwiftUI (and, worth a note in passing, Swift Data). I just wish that Apple would have been as opinionated about non-UI programming when designing the public APIs for @Observable as they were with the Combine framework. This new stuff feels penciled in and incremental, which would be OK if it weren’t absolutely fundamental to key architectural choices we have to make when building an app.
When you’re choosing between ObservableObject and @Observable, you should not limit the scope of your consideration solely to what’s best for SwiftUI. The choice you make will have structural implications on non-UI code.
Understand what you’re building before you build it.
Corrections
- I previously misidentified AsyncSequence as being released in iOS 18. It was released in iOS 13. (Thanks rdsquared).
Beware @unchecked Sendable, or Watch Out for Counterintuitive Implicit Actor-Isolation
I ran into some unexpected runtime crashes recently while testing an app on iOS 18 compiled under Swift 6 language mode, and the root causes ended up being the perils of using @unchecked Sendable in combination with some counterintuitive compiler behavior with implicit actor isolation. Rather than start at the end, I’ll walk you through how I introduced the crash, and then what I did to resolve it.
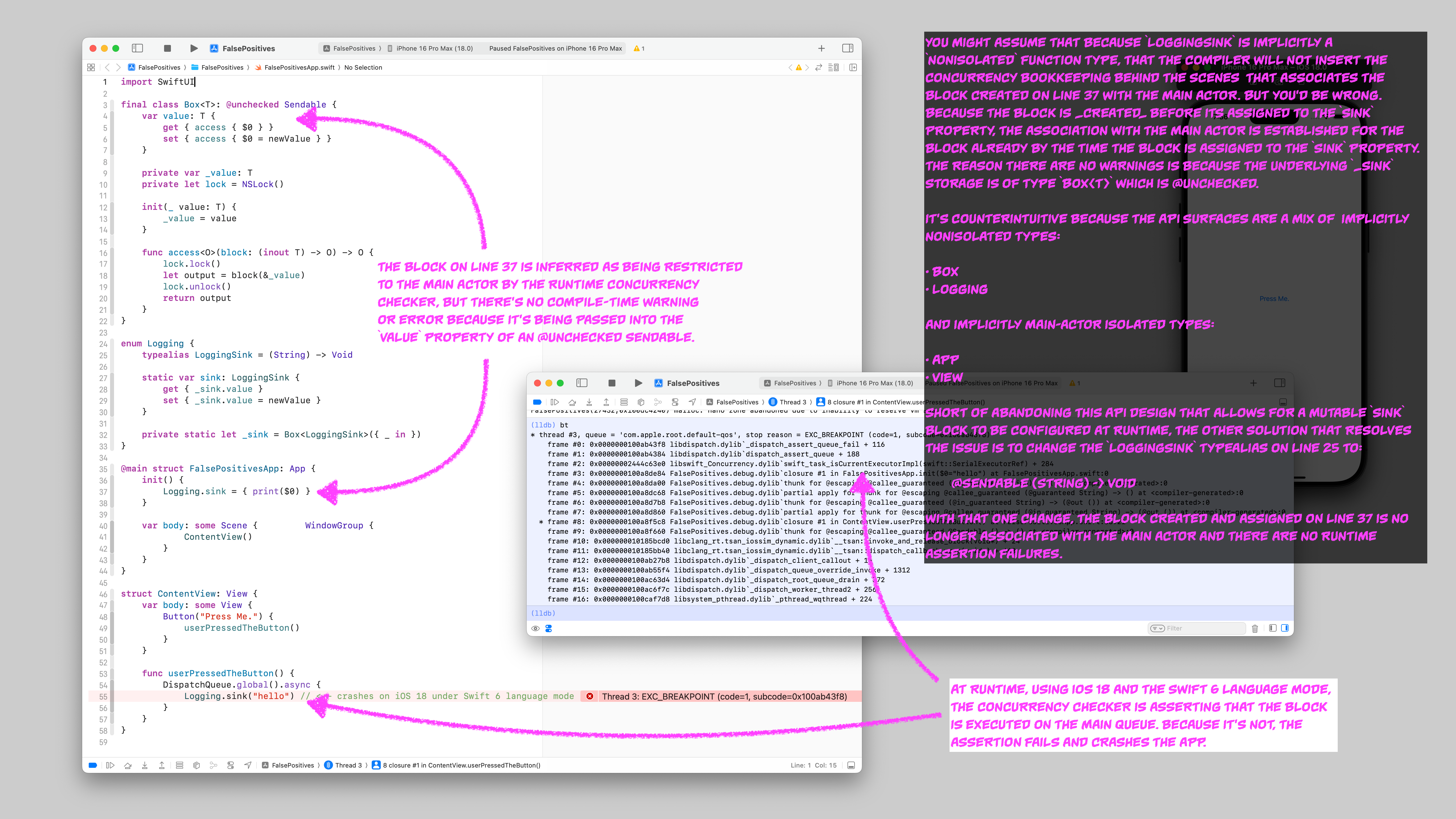
Let’s say you’re maintaining a Swift package that’s used across a number of different applications. Your library does nontrivial work and therefore your consumers need access to log messages coming from your package. Since your package cannot know how the host application wishes to capture logs, you decide to provide a public API surface that, at runtime, allows the host application to configure a logging “sink” through which all log messages from your package will flow:
public enum Logging {
/// Replace the value of `sink` with a block that routes
/// log output to your app's preferred destination:
public static var sink: (String) -> Void = { print($0) }
}
But this will not compile under Swift 6 language mode (or under Swift 5 language mode with additional concurrency checks enabled):
Static property 'sink' is not concurrency-safe because it is nonisolated global shared mutable state
Womp-womp. As the maintainer of my Swift package, since Swift 4 I have been doing the legwork in the real world, through documentation and code review, to make sure that none of my consumers are mutating the sink property except exactly once, early during app launch, before anything could be accessing it. It’s a mitigated risk. But under Swift 6, these kinds of risk mitigations are no longer sufficient. A fix has to be made in the code. Pinky swears no longer cut it.
One option could be to convert the Logging API to something with explicit global actor isolation, say via the Main Actor:
public enum Logging {
// I added `@MainActor` below:
@MainActor public static var sink: (String) -> Void = { print($0) }
}
I wouldn’t recommend this option unless all the logging in your package is already coming from code isolated to the main actor. Otherwise, you’ll have to edit many, many call sites from a synchronous call:
foo()
Logging.sink("the message goes here")
bar()
to dispatch asychronously to the main queue:
foo()
DispatchQueue.main.async {
Logging.sink("the message goes here")
}
bar()
Another problem with that change is that it dumps telemetry code (string interpolation, etc.) onto the main queue where it’s not desirable to occur, since it may degrade user interface code execution and introduce scroll hitches.
You might instead propose a more radical change that uses a non-global actor as a shared singleton so that existing synchronous read/write access can be preserved, obscuring the asynchronous details behind the scenes:
enum Logging {
// NOTE: the addition of `@Sendable`
typealias LoggingSink = @Sendable (String) -> Void
static var sink: LoggingSink {
get {
{ message in Task {
await plumbing.log(message: message)
} }
}
set {
Task {
await plumbing.configure(sink: newValue)
}
}
}
private static let plumbing = Plumbing()
private actor Plumbing {
var sink: LoggingSink = { print($0) }
func log(message: String) {
sink(message)
}
func configure(sink: @escaping LoggingSink) {
self.sink = sink
}
}
}
This second option compiles without warnings or errors, even with the strictest concurrency checks that are enabled intrinsically when compiling under Swift 6 language mode. It also behaves as expected at runtime. This is a potential option, however it didn’t occur to me until writing this blog post. What occurred to me instead was to find a way to use locking mechanisms to synchronize access to the static var mutable property. What happened next led me down a path to some code that (A) compiled without warnings or errors but (B) crashed hard at runtime due to implicit actor isolation assertion failures.
It’s this other approach that I want to walk you through, since you might be as tempted as I was to take this path and might be lulled into a false sense of optimism by the lack of compiler warnings.
TL;DR: Seriously, beware the perils of @unchecked Sendable, it hides more sins than you might guess.
Let’s revisit the original code sample, trimming some fluff for conversational purposes.:
enum Logging {
static var sink: (String) -> Void = { ... }
// Error: Static property 'sink' is not concurrency-
// safe because it is nonisolated global shared
// mutable state
}
We can resolve the compiler error by making sink a computed property backed by something that the compiler will accept. Let’s introduce a generic type Box<T> that is @unchecked Sendable and can be the backing storage for our property:
final class Box<T>: @unchecked Sendable {
var value: T
init(_ value: T) {
self.value = value
}
}
(Side note: I have, for purposes of this blog post, omitted the use of a locking mechanism to synchronize access to the value property. Such locking ensures that data races are, in practice, not possible. It doesn’t have bearing on the discussion that follows, however, because it amounts to a pinky swear that the Swift compiler cannot verify. It’s really too bad there isn’t a language-level support for this pattern that is concurrency checkable instead of only concurrency ignorable.)
Without the @unchecked Sendable, we’d get a compiler error down below when we try to use a Box<LoggingSink> to store our property:
enum Logging {
typealias LoggingSink = (String) -> Void
static var sink: LoggingSink {
get { _sink.value }
set { _sink.value = newValue }
}
private static let _sink = Box<LoggingSink>({ print($0) })
}
Since we have included the @unchecked Sendable on our Box type, that ☝🏻 there compiles without warnings or errors. We’ve converted a mutable static var sink property to a computed property backed by an object that the concurrency checker ignores. This preserves our existing API. It also carries forward all of the existing risks which our consumers have pinky-sworn with us not to get wrong. We could stop here. However, when we wire this code up in a sample project, we encounter a crash at runtime on iOS 18:
@main
struct MyApp: App {
init() {
Logging.sink = { print($0) }
}
var body: some Scene { ... }
}
struct ContentView: View {
var body: some View { ... }
func userPressedTheButton() {
DispatchQueue.global().async {
Logging.sink("hello") // <-- CRASH
}
}
}
Here’s the output from the bt command in lldb:
* thread #3, queue = 'com.apple.root.default-qos', stop reason = EXC_BREAKPOINT (code=1, subcode=0x101bd43f8)
frame #0: 0x0000000101bd43f8 libdispatch.dylib`_dispatch_assert_queue_fail + 116
frame #1: 0x0000000101bd4384 libdispatch.dylib`dispatch_assert_queue + 188
frame #2: 0x0000000244f8a400 libswift_Concurrency.dylib`swift_task_isCurrentExecutorImpl(swift::SerialExecutorRef) + 284
frame #3: 0x0000000100838994 FalsePositives.debug.dylib`closure #1 in FalsePositivesApp.init($0="hello") at FalsePositivesApp.swift:0
frame #4: 0x00000001008385ec FalsePositives.debug.dylib`thunk for @escaping @callee_guaranteed (@guaranteed String) -> () at <compiler-generated>:0
frame #5: 0x000000010083849c FalsePositives.debug.dylib`thunk for @escaping @callee_guaranteed (@in_guaranteed String) -> (@out ()) at <compiler-generated>:0
* frame #6: 0x0000000100839850 FalsePositives.debug.dylib`closure #1 in ContentView.userPressedTheButton() at FalsePositivesApp.swift:40:21
frame #7: 0x00000001008398a0 FalsePositives.debug.dylib`thunk for @escaping @callee_guaranteed @Sendable () -> () at <compiler-generated>:0
frame #8: 0x0000000101bd0ec0 libdispatch.dylib`_dispatch_call_block_and_release + 24
frame #9: 0x0000000101bd27b8 libdispatch.dylib`_dispatch_client_callout + 16
frame #10: 0x0000000101bd55f4 libdispatch.dylib`_dispatch_queue_override_invoke + 1312
frame #11: 0x0000000101be63d4 libdispatch.dylib`_dispatch_root_queue_drain + 372
frame #12: 0x0000000101be6f7c libdispatch.dylib`_dispatch_worker_thread2 + 256
frame #13: 0x000000010099b7d8 libsystem_pthread.dylib`_pthread_wqthread + 224
This stack of method calls jumps out at us:
0: _dispatch_assert_queue_fail
1: dispatch_assert_queue
2: swift_task_isCurrentExecutorImpl(swift::SerialExecutorRef)
That’s a runtime assertion causing the app to crash. It appears to be asserting that some specific queue managed by a task executor is the expected queue. Since we aren’t using any other actors here except the Main Actor (implicitly the Main Actor since SwiftUI View and App protocols are implicitly isolated to the Main Actor), we have to assume that the runtime is doing the equivalent of this:
dispatch_assert_queue(.main)
But why? Our LoggingSink function type is implicitly nonisolated:
typealias LoggingSink = (String) -> Void
Same goes for the rest of the Logging namespace and the Box class. There’s nothing in our logging API surface that would imply Main Actor isolation. Where is that isolation being inferred?
It turns out that the implicit Main Actor isolation is getting introduced by MyApp where we’ve supplied the LoggingSink:
struct MyApp: App {
init() {
Logging.sink = { print($0) }
}
The App protocol declaration requires @MainActor:
@available(iOS 14.0, macOS 11.0, tvOS 14.0, watchOS 7.0, *)
@MainActor @preconcurrency public protocol App {
Therefore that init() method is isolated to the Main Actor. But our Logging.sink member is not isolated to the Main Actor. It’s implicitly nonisolated, so why is the compiler inferring Main Actor isolation for the block we pass to it?
I will offer an educated guess about what’s happening here. I believe it’s a combination of three factors:
1) It is not possible to explicitly declare a function type as nonisolated.
You cannot include the nonisolated keyword as part of the type declaration for a function. We could not, for example, write our app’s initializer like this:
struct MyApp: App {
init() {
// Cannot find type 'nonisolated' in scope
let sink: nonisolated (String) -> Void = { print($0) }
Logging.sink = sink
}
This is an important distinction because it has bearing on the next factor that I believe is contributing to the behavior:
2) Closures (may? always?) implicitly inherit the actor isolation where they are created.
If we rewrote our app’s initializer to look like this instead:
@main struct FalsePositivesApp: App {
init() {
let closure: (String) -> Void = { print($0) }
Logging.sink = closure
}
You might assume that the closure variable couldn’t possibly be isolated to the Main Actor. It’s right there in the type of the function: (String) -> Void. According to the language rules as I understand them, function types that are not explicitly isolated to a global actor are implicitly nonisolated. But when we run the app with ☝🏻 that code, we get the same result: a runtime assertion failure and a crash on dispatch_assert_queue, as if our closure had the type @MainActor (String) -> Void instead. For some reason here, the Swift 6 compiler is implicitly associating that { print($0) } closure with the Main Actor without informing us that it is doing so. I would argue that this is, at least in part, a defect in the compiler. This implicit Main Actor isolation is erroneous. But part of the problem is on us, because we’ve been using @unchecked Sendable, which causes the compiler to suppress errors that would otherwise bring related problems to the surface. This leads us to the third factor contributing to the observed behavior.
3) @unchecked Sendable suppresses compile-time concurrency checks of functions used as stored instance members, but does not suppress run-time concurrency checks when those functions are executed.
Phew, that’s a mouthful. Let’s unpack it a bit.
- functions used as stored instance members - This means an instance property like the
var value: Tin ourBoxtype. - suppresses compile-time checks - The compiler ignores potential data races in the creation and usage of the stored function at compile time.
- but does not suppress run-time concurrency checks - Any actor isolation assertions that slip into the code that were suppressed at compile time are not also suppressed at run-time, even if those assertions are erroneous and the code is not actively committing data races.
In other words, code that compiles OK may crash at run-time on false positive assertions in code that turns out not to be a legitimate problem.
I do not consider the supression of compile-time errors a bug or a defect. Slapping @unchecked Sendable on something is brazenly constructing a footgun. The Swift 6 compiler is justified in suppressing warnings and errors, and we have been “asking for it” if our app encounters actual data races.
However, I do think it’s impolite for the runtime to enforce isolation assertions on code that has explicitly been asked to suppress such assertions via @unchecked, especially since they are just naive assertions about the current dispatch queue, not introspection of the actual content of the function being executied. Pinky swears, documentation, peer review, and long stretches of production battle-hardening should be a sufficient counter to any gripes that the Swift 6 runtime may have about our desire to ignore actor isolation. The fact that it is possible for the runtime to not honor my intent here is, I’d argue, if not a defect, at least an annoyance. Let me build my footguns. I promise to only shoot between adjacent toes.
Putting All Three Together
Let’s see how all three factors come together to create this problem, where compile time seems OK but run-time crashes. Let’s start by, for sake of argument, rewriting our app’s initializer to this:
enum Example {
static func runThisOnMainActor(
closure: @escaping (String) -> Void
) {
DispatchQueue.main.async {
// ERROR: Sending 'closure' risks
// causing data races:
closure("example")
}
}
}
@main struct FalsePositivesApp: App {
init() {
let closure: (String) -> Void = { print($0) }
Example.runThisOnMainActor { message in
closure(message)
}
}
That will not compile under Swift 6 language mode because we cannot pass closure into DispatchQueue.main.async without declaring @Sending on the runThisOnMainActor method’s closure argument. The Swift 6 compiler is really good at catching all kinds of flavors of this potential for data races, even if you try stuffing @unchecked Sendable into the mix:
final class Example: @unchecked Sendable {
func runThisOnMainActor(
closure: @escaping (String) -> Void
) {
DispatchQueue.main.async {
// ERROR: Sending 'closure' risks
// causing data races:
closure("example")
}
}
}
@main struct FalsePositivesApp: App {
init() {
let closure: (String) -> Void = { print($0) }
Example().runThisOnMainActor { message in
closure(message)
}
}
But it does have a loophole: functions as stored instance members. If you have a type that is @unchecked Sendable with a stored instance member that’s a function, then all the compile-time concurrency checking around that function is suppressed. The following code sample compiles without warnings on Swift 6, but crashes at runtime with the assertion failure we’ve been discussing:
final class Example: @unchecked Sendable {
var closure: (String) -> Void = { _ in }
}
@main struct FalsePositivesApp: App {
init() {
let closure: (String) -> Void = { print($0) }
let example = Example()
example.closure = closure
DispatchQueue.global().async {
example.closure("crash!") // CRASHES
}
}
What’s so strange here is the nature of our closure local variable. It’s implicitly nonisolated, but the compiler is baking Main Actor isolation checks into the { print($0) } body of the closure. There’s no compile-time warning about any of this because of the loophole in functions as stored instance members of unchecked sendables.
How To Fix This
Assuming that you just really, really, really want to keep that @unchecked Sendable in the mix, the way to resolve this issue is to change the function type declaration of the LoggingSink from:
typealias LoggingSink = (String) -> Void
to:
typealias LoggingSink = @Sendable (String) -> Void
With that one change, it no longer becomes possible to set the value of Logging.sink to anything other than a sendable function:
@main struct FalsePositivesApp: App {
init() {
let closure: (String) -> Void = { print($0) }
// ERROR: Converting non-sendable function
// value to '@Sendable (String) -> Void'
// may introduce data races:
Logging.sink = closure
}
And the following will both compile without warnings or errors, and will not violate an assertion at runtime:
@main struct FalsePositivesApp: App {
init() {
Logging.sink = { print($0) }
}
Good luck out there.
Update, November 13th 2024
Got some helpful responses via Mastodon yesterday.
Matt Massicotte writes:
What’s happening here is the compiler is reasoning “this closure is not Sendable so it couldn’t possibly change isolation from where it was formed and therefore its body must be MainActor too” but your unchecked type allows this invariant to be violated. This kind of thing comes up a lot in many forms, and it’s hard to debug…
Both Matt Massicotte and Rob Napier also brought up the Mutex struct from the Synchronization module, which I keep forgetting about because it has an iOS 18 minimum and is therefore not available to me on my projects. Mutex is analogous to the Box<T> class pictured in my screenshot above. Let’s look at Mutex’s generated interface alongside the one for Box<T> to compare and contrast (trimming some boilerplate for clarity).
Here’s Mutex:
struct Mutex<Value> : ~Copyable where Value : ~Copyable {
func withLock<Result, E>(
_ body: (inout Value) throws(E) -> sending Result
) throws(E) -> sending Result where E : Error, Result : ~Copyable
}
extension Mutex : @unchecked Sendable where Value : ~Copyable {
}
And here’s Box:
final class Box<T>: @unchecked Sendable {
func access<Output>(block: (inout T) -> Output) -> Output
}
First, note how both of them require @unchecked in order to conform to Sendable. This is because there is no language-level primitive or concurrency structure that permit synchronized synchronous access to be checked for correctness by the concurrency checker. At best we can only suppress false positives. It sure would be nice if there was a language-level way to enforce correctness, though I suppose that will matter less in the future once apps can start declaring an iOS 18 minimum and rely on Mutex for these needs.
But prior to iOS 18, one has to roll their own alternative to Mutex in order to implement synchronous access to a synchronized resource, which is what my Box<T> example class is attempting to do. But note one key difference: Box is generic over anything. It’s just T. But Mutex enforces an additional constraint: ~Copyable. This means “not Copyable”, and it has unique behavior among protocols in Swift. I recommending reading (and rereading multiple times until you can comprehend it) the Copyable documentation. There are some truly astounding bits of information in there:
Astounding Bit #1) All generic type parameters implicitly include Copyable in their list of requirements.
If your codebase has a generic type, it’s using Copyable already. That means that my Box<T> type, despite what I said above, does have an implicit constraint:
final class Box<T: Copyable>
All classes and actors implicitly conform to Copyable, and it’s not possible to declare one that doesn’t. All structs and enums implicitly conform to Copyable, but it is possible to state definitely that one does not. Check this out:
final class Box<T> {
var value: T
init(_ value: T) {
self.value = value
}
}
struct AintCopyable: ~Copyable {
var foo = 32
}
let box = Box(AintCopyable())
// ERROR: Generic class 'Box' requires that
// 'AintCopyable' conform to 'Copyable'
Astounding Bit #2) Both copyable and noncopyable types can conform to protocols or generic requirements that inherit from ~Copyable.
This is counterintuitive to say the least. You would think “not copyable” would exclude, as a logical categorization, anything that is “copyable”. But you’d be wrong, at least when it comes to generics and protocol requirements. Here’s an example based on the one given in the Copyable documentation:
protocol HeadScratching: ~Copyable {
var foo: Int { get set }
}
struct IsCopyable: Copyable, HeadScratching {
var foo = 32
}
struct AintCopyable: ~Copyable, HeadScratching {
var foo = 32
}
That ☝🏻 there compiles without warnings or errors. This next example almost compiles, except for some concurrency errors I will explain in a moment, the explanation of which will bring us to another Astounding Bit about the Copyable protocol:
final class Box<T: ~Copyable> {
var value: T
init(_ value: T) {
self.value = value
}
}
struct AintCopyable: ~Copyable {
var foo = 32
}
struct IsCopyable: Copyable {
var foo = 32
}
// Allowed:
let boxA = Box(AintCopyable())
// Also allowed:
let boxB = Box(IsCopyable())
Astounding Bit #3) Non-copyable values cannot be parameterized without specifying their ownership.
To put it another way, look at this compiler error from my preceding example:
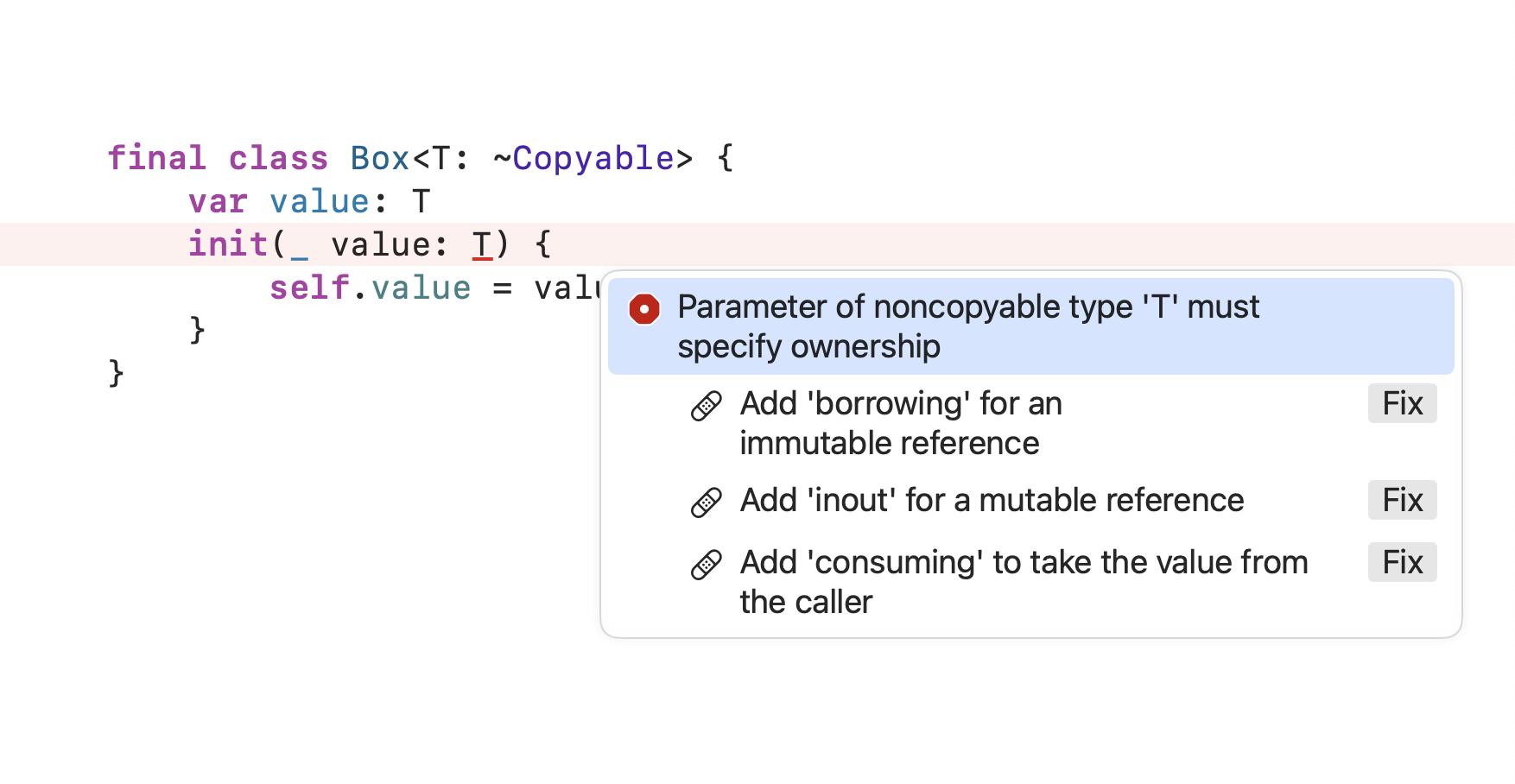
You must specify one of the following ownership options for the value parameter since it is required to be non-copyable. The borrowing option is not useful for our purposes here because we’re trying to construct a threadsafe mutable reference to a shared value, and borrowing would not allow us to store value in a property. The inout option is slightly more usable, because it allows us to store value in a property, however it permits both Box and the caller using a Box to have read/write access to the same piece of data. That’s not going to fly when we’re trying to prevent data races. That leaves only the consuming option, which is what you see in Mutex’s initializer:
struct Mutex<Value: ~Copyable> {
init(_ initialValue: consuming sending Value) {
...
}
This all bears repeating: the compiler forces you to select an explicit memory ownership for any generic parameter that is noncopyable (\~Copyable). This makes \~Copyable especially useful for use with data synchronization utilities like Mutex. We want to be as explicit as possible, at compile time, about where and how data is permitted to mutate.
Astounding Bit #4) Non-copyable parameters with consuming ownership help diagnose concurrency issues at compile time.
Once you’ve selected the consuming ownership, there are some useful secondary effects that cascade from that choice. Let’s look at a contrived example to learn more:
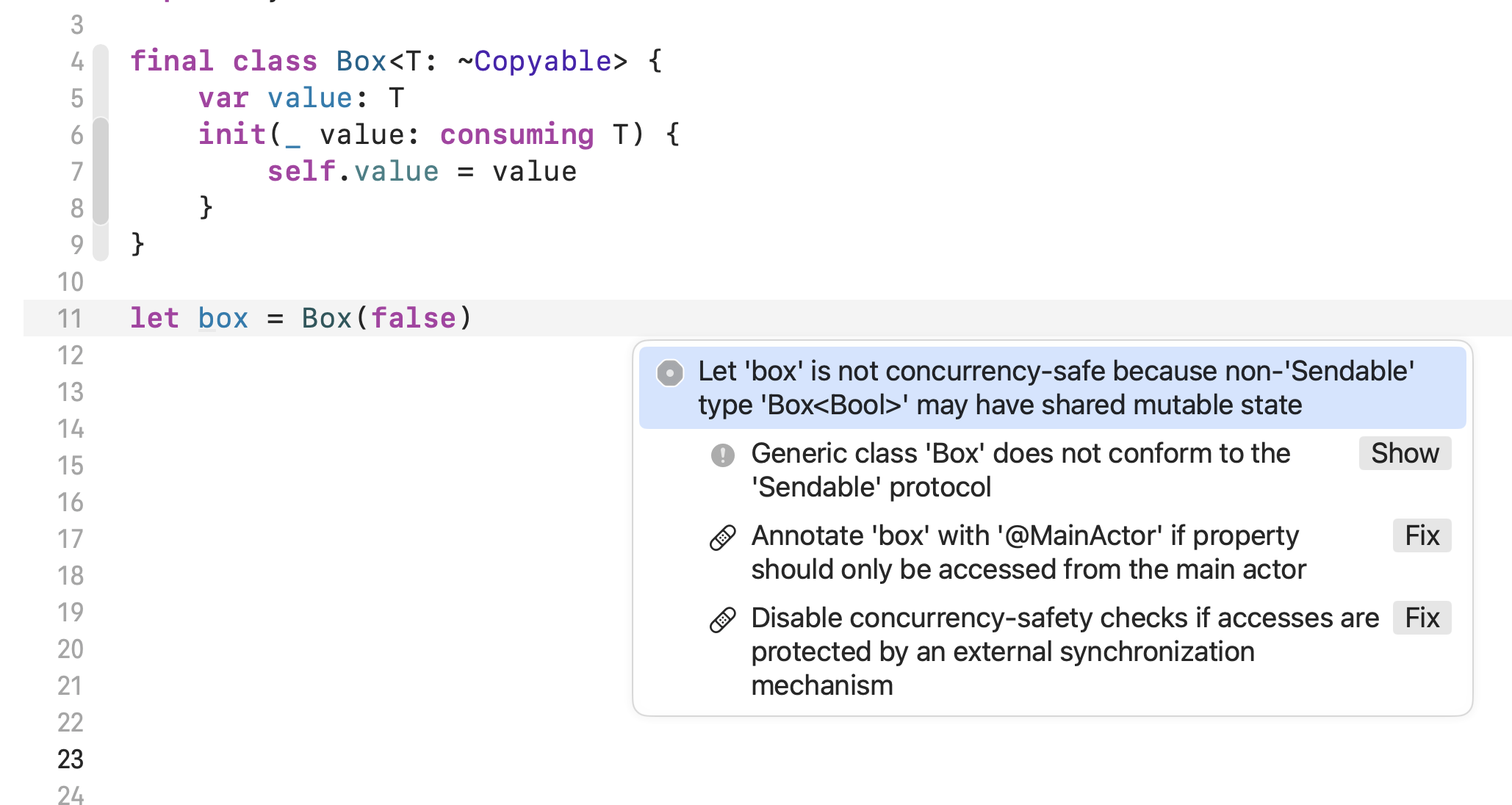
The Swift 6 compiler is able to deduce that we’ve introduced a potential data race. The box declaration is at a global scope, and contains mutable state. The fixits in that screenshot list several options. Let’s use @unchecked Sendable and add our own locking mechanism to prevent a data race:
final class Box<T: ~Copyable>: @unchecked Sendable {
private var _value: T
private let lock = NSLock()
init(_ value: consuming T) {
self._value = value
}
func withLock<Output: ~Copyable>(
_ body: (inout T) -> Output
) -> Output {
lock.lock()
defer { lock.unlock() }
return body(&_value)
}
}
let box = Box(false)
That all compiles now, without warnings or errors. We’ve still got a var value: T property, but it’s a computed property that synchronizes access via the withLock method, which uses an NSLock to synchronize concurrent reads and writes. But this example is still just using a Bool, which is pretty contrived. What happens if we go back to my original example above of a (String)-> Void function type instead of a Bool?
let sharedBox = Box<(String) -> Void>({ print($0) })
@main struct FalsePositivesApp: App {
init() {
sharedBox.withLock {
$0 = { print("custom: \($0)") }
}
}
var body: some Scene { WindowGroup { ContentView() } }
}
struct ContentView: View {
var body: some View {
Button("Press Me.") {
userPressedTheButton()
}
}
func userPressedTheButton() {
DispatchQueue.global().async {
let block = sharedBox.withLock { $0 }
block("print me") // <--- CRASHES
}
}
}
It compiles without errors, but it crashes at runtime with the same main queue assertion we saw earlier in this blog post. What gives? Well, we’ve omitted something from our definition of the withLock method that is seen in Mutex’s equivalent method: a bunch of sending keywords. This keyword was introduced in SE-0430. It’s a bit wonkish to explain, but it allows a function parameter and/or result to indicate to the compiler that it might be sent over a concurrency isolation boundary (like, say, from the main actor to some other region). It’s akin to @Sendable, but less dramatic. It patches some holes in the concurrency checker that otherwise made it difficult to do things like: prevent concurrent access to a non-Sendable object after it got passed as a parameter into an actor’s initializer. The proposal is worth reading carefully, I won’t summarize it more than that now.
Here’s our Box’s withLock method with those sending keywords added:
func withLock<Output: ~Copyable>(
_ body: (inout sending T) -> sending Output
) -> sending Output
What happens if we try to compile now? Check it out:
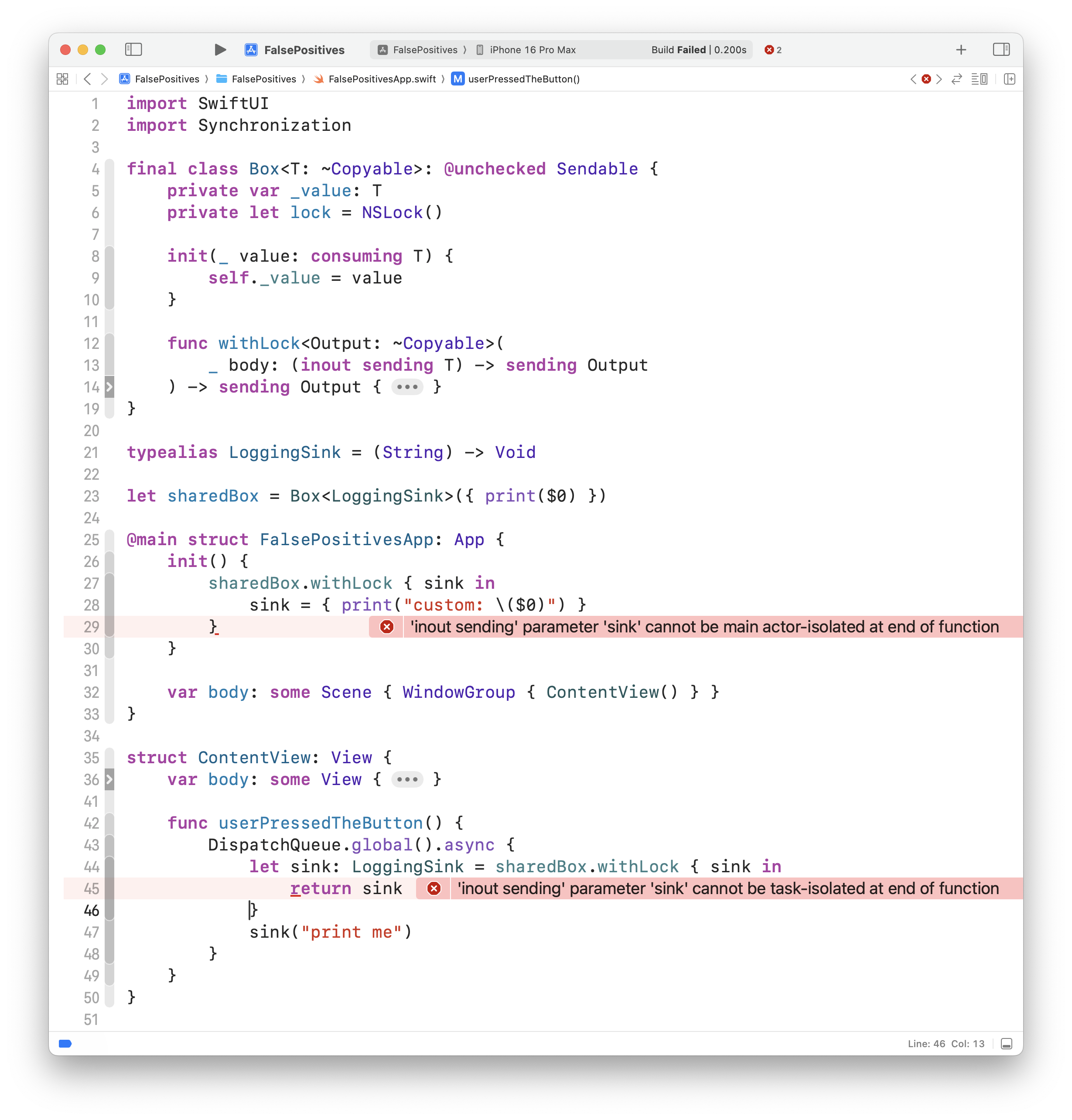
The text of those errors is underwhelming, but their presence is helpful. It’s detected that we’re sending a non-Sendable function type either from the Main Actor into some unspecified region (“…cannot be main actor-isolated at…”), or from one unspecified region into another unspecified region (“…cannot be task-isolated at…”). The solution is what we discovered earlier: to require our LoggingSink function type to be @Sendable:
typealias LoggingSink = @Sendable (String) -> Void
With that one change, the compiler errors go away and the runtime crashes are resolved, too.
OK, But why are you blathering on about this? Didn’t we already figure that out earlier?
Here’s why I think this matters. There’s one crucial difference between yesterday’s implementation of Box<T> and today’s implementation Box<T: ~Copyable>: the noncopyable version detected, at compile time, that we were sending a non-Sendable function type across isolation regions in a way that would trigger runtime actor isolation checks. The version that is implicitly copyable does not expose this information to the concurrency checker at compile time. This is true even though both implementations of Box use @unchecked Sendable. The internals of Box are still unchecked by the concurrency checker, but the values passed into and out of the Box are better checked when ~Copyable and consuming and sending are in the mix.
So if, like me, you are unable to use Mutex yet because it requires iOS 18 or later and, like me, you are on the hook to write a replacement that supports earlier OS versions, I think you and I both should consider mimicking the design of Mutex, in particular its compile time checks via ~Copyable, consuming, and sending.
How Do You Know Whether or Not SwiftUI Previews and Preview Content Are Excluded From App Store Builds?
I’ve found what I believe to be a bug, or at least deeply disappointing behavior, in Xcode’s treatment of SwiftUI previews. I’ll put an explanation together in the paragraphs that follow, but the TL;DR is: I think you’ll probably want to start wrapping all your SwiftUI Previews and Preview Content Swift source code in #if DEBUG active compilation condition checks.
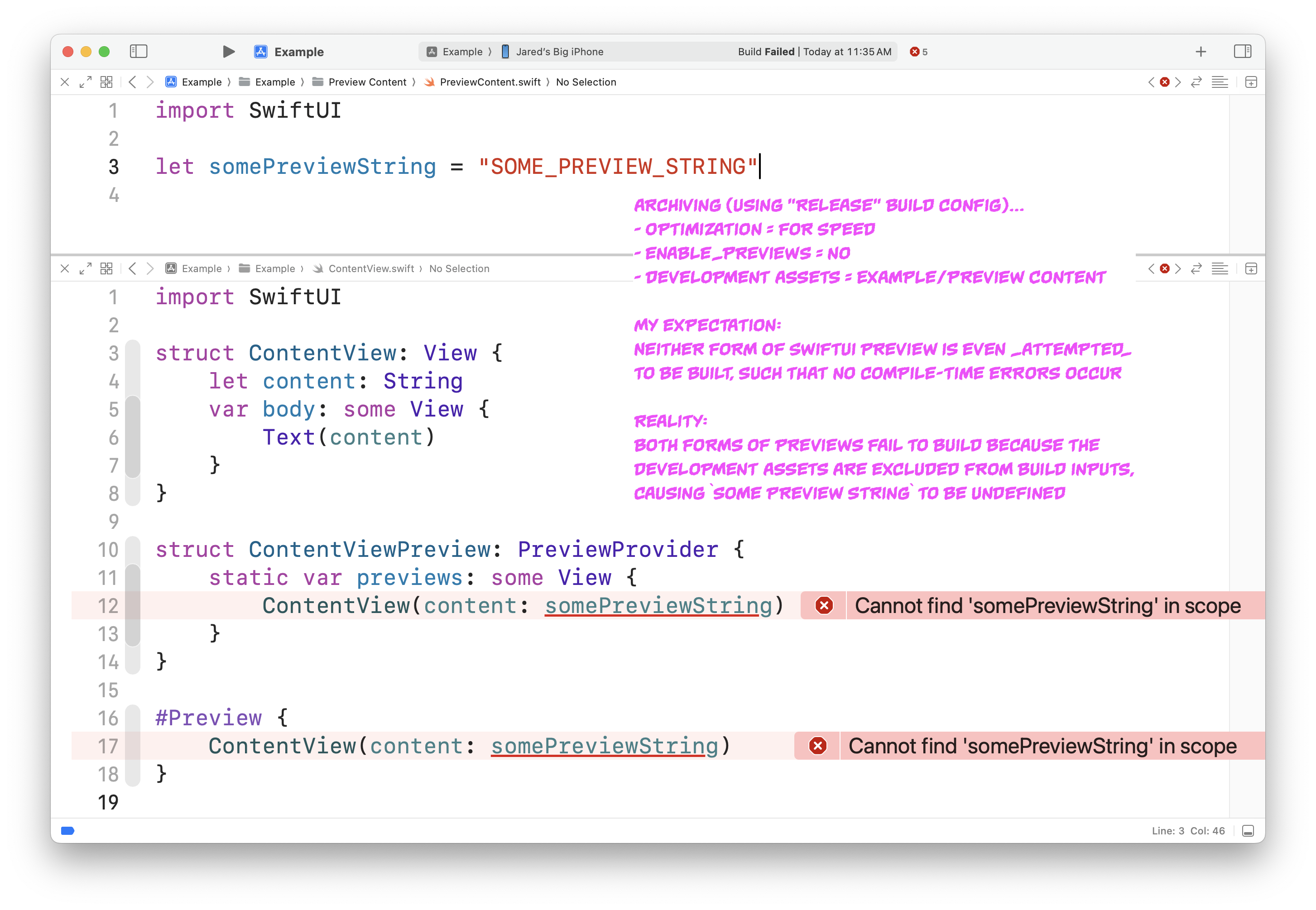
Screenshot of an Archive action build failure.
SwiftUI previews are, if you consider it from a broader perspective, comprised of two kinds of source code:
-
Preview proper: - The actual
#PrevieworPreviewProvidersource code, typically at the bottom of the participating SwiftUI file. -
Development Assets: - Ancillary source (and assets) under a particular directory whose contents should only be used to populate SwiftUI previews. The default name for this directory (in
File/New...) projects isPreview Content.
The SwiftUI preview dream is supposed to be this:
-
Dream Part 1: I write
#Preview { ... }or aPreviewProviderat the bottom of my file. -
Dream Part 2: I stash any images, assets, or source code (representative data) in the Preview Content directory of Development Assets.
-
Dream Part 3: Xcode ensures that both my Preview proper, and all my Development Assets, are omitted from App Store builds.
The reality is less than that ideal:
-
#PreviewandPreviewProvidersource code is stripped out of any build where Swift Optimizations are anything above-Onone. It (hilariously) does not matter whether or not you’ve got theENABLE_PREVIEWSbuild setting set toNo, or whether your build configuration is namedReleaseor not. They are included in any unoptimized build. -
Once more, with feeling: Preview source code is included in any unoptimized build.
-
Note I said, two bullets ago, “stripped out”. Previews are actually built in all builds, but they are later stripped out of the compiled binary as part of code optimization. They aren’t skipped altogether, not even for optimized builds. This will have bearing on the bullet points that follow. . . .
-
Development Assets are not always built. They are omitted at the front end of the build process during Archiving only (i.e. running “Archive” from the Xcode GUI menu, or the
archivexcodebuild command), and even then only if you’ve defined theDEVELOPMENT_ASSET_PATHSbuild setting. Any images, asset catalogs, or source files under those paths are excluded from build input. If you aren’t using “Archive”/archive, you won’t see a build error! -
This means that if you’ve got a SwiftUI Preview that depends upon
.swiftsource code, any “Archive”/archiveattempt will fail at build time because the Preview depends upon source code that no longer exists among the build inputs.
There are several workarounds, none of which are spectacular:
-
Stop using SwiftUI previews. - Boo, a non-starter.
-
Leave Development Assets hanging around in optimized builds. - This is done by removing the definition of the
DEVELOPMENT_ASSET_PATHSbuild setting. Also “Boo” because the whole point of Development Assets is that you don’t want them showing up in App Store builds. -
Wrap all SwiftUI previews in
#if DEBUGactive compilation condition checks. - Unless you’ve overridden new project defaults, Release build configurations do not defineDEBUGas a Swift active compilation condition. Wrapping all your SwiftUI Previews in#if DEBUGis a semi-bulletproof solution that will ensure your Previews don’t break optimized builds. But it doesn’t, on its own, prevent development assets from creeping into App Store builds because you might have forgotten to define theDEVELOPMENT_ASSET_PATHSbuild setting. If the build setting is missing, your development assets are potentially delivered in App Store builds. I say “potentially” because such a build is, after all, optimized, and therefore if no production code is actually accessing the development asset source code, it’s possible it may be optimized out of the final binary. -
Wrap all SwiftUI previews AND Development Assets Swift source in
#if DEBUGactive compilation condition checks. - This is the only solution, short of improvements to Xcode itself, that ensures that Previews don’t break optimized builds and that Development Assets source code doesn’t leak into App Store builds.
That’s the long-winded explanation.
Until and unless Apple makes ergonomic improvements to align SwiftUI Preview and Development Asset conditional compilation techniques, I recommend wrapping both kinds of source code in #if DEBUG to prevent accidental slippage of test data and source into production code, as well as to prevent unexpected build failures on multitenant hardware (for teams that build for App Store in CI, these build failures often don’t appear except on unattended machines around the time a release is being cut, making them perniciously difficult to spot during day-to-day code review).
Be Careful When You Initialize a State Object
I’m going to share some best practices when using @StateObject property wrappers, things learned the hard way, via some bugs that were difficult to diagnose and nearly impossible to notice during code review—unless one knows what to look for.
The short version is this: if you have to explicitly initialize a @StateObject, pay close attention to the fact that the property wrapper’s initialization parameter is an escaping closure called thunk, not an object called wrappedValue. Do all the wrapped object initialization and prep inside the closure, or else you’ll undermine the performance benefits that likely motivated you to use @StateObject in the first place.
Several years ago, before the @StateObject property wrapper was introduced, if your SwiftUI view needed to create and own an object to perform view-specific duties that can only be performed by a reference type (say, to coordinate some Combine publishers), the only option was an @ObservedObject:
struct MyView: View {
@ObservedObject private var someObject = SomeObject()
}
A chief problem with this API is that the wrapped object’s initializer (in this example the = SomeObject()) would be run every time MyView, the struct, was initialized. Since this view is just a child of some other ancestor view, any time the ancestor’s body property gets accessed, MyView will be initialized anew, causing SomeObject() to be initialized again and again:
struct SomeAncestor: View {
var body: some View {
MyView() <-- gets invoked anytime SomeAncestor.body is read
}
}
Remember that a SwiftUI View is not the view object you see on screen, but rather just a template describing the view object that will be created for you at a later time. Since the body property of a view returns merely a template, the guts of the SwiftUI framework operate under the assumption that a body can be accessed as many times as needed to recompute these templates.
To prevent unwanted successive initialization of wrapped objects, the @StateObject property wrapper was introduced. It is often a simple drop-in replacement for an @ObservedObject:
struct MyView: View {
@StateObject private var someObject = SomeObject()
}
With this change, anytime SwiftUI traverses the view hierarchy, recursively calling into body property after body property, if possible, the storage mechanism within the @StateObject property wrapper will be carried forward to the new view struct without causing the wrapped object to be initialized again. It’s a bit magical, but honestly a bit too magical, since what I’ve just described contains two hidden details that need close attention.
First, when I wrote “…if possible…” in the previous paragraph, I was referring to the fact that SwiftUI needs to be able to make the determination that two instances of a given view struct should be interpreted as being templates for the exact same on-screen view object. The term for this concept is “identity”. Two View structs are understood to have the same identity if they share the same identifier. This identifier can be either explicit, or implied.
Explicit identification looks like this:
struct SomeAncestor: View {
var body: some View {
MyView()
.id("the-one-true-view")
}
}
Implicit identification is harder to grok. Sometimes it can be inferred from the combination of an Identifiable model in conjunction with a ForEach:
struct Thing: Identifiable {
let id: String <--- required
let name: String
}
struct SomeAncestor: View {
let stuff: [Thing]
var body: some View {
ForEach(stuff) { thing in
MyView(thing)
}
}
}
In the above example, the particular init method of the ForEach accepts a collection of Identifiable model values, which allows the guts of the ForEach body to assign identifiers to each MyView, automatically on your behalf, using the id properties of the model values. Here’s that initializer from SwiftUI’s public interface:
extension ForEach
where ID == Data.Element.ID,
Content : AccessibilityRotorContent,
Data.Element : Identifiable
{
init(
_ data: Data,
@AccessibilityRotorContentBuilder content: @escaping (Data.Element) -> Content
)
}
SwiftUI has other mechanisms to try to infer identity, but if you’re not explicitly providing identity for a view that owns a @StateObject, it’s possible that your wrapped object is getting intialized more often than you desire. Setting breakpoints at smart places (like the init() method of your wrapped object) is a helpful place to look.
I wrote that there were two hidden details hiding in the magic of @StateObject. I just described the first one, it’s hidden reliance on view identity, but there is another issue that’s particularly subtle, and that’s the mechanism by which it’s possible for a @StateObject to avoid duplicate initializations of its wrapped object. The best way to see it is by looking at the public interface:
@propertyWrapper
struct StateObject<ObjectType> : DynamicProperty
where ObjectType : ObservableObject
{
init(wrappedValue thunk: @autoclosure @escaping () -> ObjectType)
}
Look closely: the initialization parameter is an escaping closure called thunk, marked with the @autoclosure label. The parameter is not the object type itself. You might have assumed, like I did at first, that the initalizer looked like this:
@propertyWrapper
struct StateObject<ObjectType> : DynamicProperty
where ObjectType : ObservableObject
{
init(wrappedValue: ObjectType)
}
This might seem like an academic distinction, until you run into a situation where your view needs to explicitly initialize the @StateObject property wrapper. If you aren’t careful, it’s possible to completely undermine the benefits of StateObject.
Consider this example, which is similar to something that I actually had to do in some production code. Let’s say that I have a podcast app with a view that displays an episode’s download progress:
struct DownloadProgressView: View {
...
}
My app uses CoreData, so I have a class Episode that’s a managed object. It has some properties, among others, that track download progress for that episode:
class Episode: NSManagedObject {
@NSManaged var bytesDownloaded: Int
@NSManaged var bytesExpected: Int
...
}
I need my view to update in response to changes in those properties (and let’s say, for reasons outside the scope of this post, it isn’t possible to migrate this app to SwiftData, because it’s not ready for the limelight), which means I need to use KVO to observe the bytesDownloaded and bytesExpected properties. Since I can’t do that observation from my DownloadProgressView directly, I’ll need an intermediate object that sits between the managed object and the view:
class DownloadProgressObserver: NSObject, ObservableObject {
@Published private(set) var progress = 0
init(episode: Episode) {
super.init()
startObserving(episode)
}
}
The only thing left is to update my view to use this new class. Since nothing else in my app needs this intermediate object, it’s sensible for my view itself to be what creates and owns it, just for the lifetime of my view being on screen. Sounds like a @StateObject is a good fit:
struct DownloadProgressView: View {
@StateObject private var observer = DownloadProgressObserver(episode: WHAT_GOES_HERE)
...
}
OK, so I cannot use a default value to populate the observer, because my observer has a required initialization argument that cannot be obtained until runtime. So I need to provide an explicit initializer for my view:
struct DownloadProgressView: View {
@StateObject private var observer: DownloadProgressObserver
init(_ episode: Episode) {
let observer = DownloadProgressObserver(episode: episode)
_observer = StateObject(wrappedValue: observer)
}
}
Looks great, right? Actually, it’s really bad. Because I initialize the observer object as a separate statement, and pass a local variable as the wrappedValue, it is (sort-of, in a pseudocode-y way) equivalent to the following code:
let observer = DownloadProgressObserver(episode: episode)
_observer = StateObject(thunk: { observer })
Remember that the initialization parameter is an escaping closure called thunk. This closure is only ever run once for the lifetime that my DownloadProgressView’s associated UI object is displayed on screen. The instance returned from the one-time execution of thunk() is what gets supplied to the SwiftUI views. But my DownloadProgressView’s initializer will be run many, many times, as often as SwiftUI needs. Each time, except for the very first initialization, all those DownloadProgressObserver objects that my init body is creating end up getting discarded as soon as they’re created. If anything expensive happens inside of DownloadProgressObserver.init(episode:), that’s a ton of needless work that could degrade performance at best, or at worst, could introduce unwanted side effects (like mutating some state somewhere else).
The only safe and correct way to explicitly initialize a @StateObject is to place your wrapped object’s initialization inside the autoclosure:
struct DownloadProgressView: View {
@StateObject private var observer: DownloadProgressObserver
init(_ episode: Episode) {
_observer = StateObject(wrappedValue:
DownloadProgressObserver(episode: episode)
)
}
}
That ensures that the object is initialized exactly once. This is particularly important to remember if preparing your wrapped object requires several statements:
struct MyView: View {
@StateObject private var tricky: SomethingTricky
init(_ model: Model, _ baz: Baz) {
_tricky = StateObject(wrappedValue: {
let foo = Foo(model: model)
let bar = Bar(model: model)
let tricky = SomethingTricky(
foo: foo,
bar: bar,
baz: baz
)
return tricky
}())
}
}
It would be natural to want to write all those statements in the main init body, and then pass the tricky instance as the wrappedValue: tricky parameter, but that would be wrong.
Hopefully I’ve just saved you an hour (or more) of fretful debugging. Apple, to their credit, did include warnings and gotchas in their documentation, which I could have read before hand, but didn’t think to read it:
If the initial state of a state object depends on external data, you can call this initializer directly. However, use caution when doing this, because SwiftUI only initializes the object once during the lifetime of the view — even if you call the state object initializer more than once — which might result in unexpected behavior. For more information and an example, see StateObject.
Side note: this whole debacle I created for myself points out the risks of using @autoclosure parameters. Unless one pauses on a code completion and jumps into the definition, it’s very, very easy to mistake an autoclosure for a plain-old parameter. An end user like me is not entirely to blame for my mistake, given how most (all?) other property wrappers in SwiftUI do not use autoclosures.
Scaled Metric Surprises on iOS & iPadOS
UIKit’s UIFontMetrics.scaledValue(for:) and SwiftUI’s @ScaledMetric property wrapper offer third-party developers a public means to scale arbitrary design reference values up and down relative to dynamic type size changes. Please be aware, however, that scaled values are not scaled proportionally with the default point sizes of the related text style. They scale according to some other scaling function that differs considerably from the related text style. An example will help illustrate this. Consider the following code:
let metrics = UIFontMetrics(forTextStyle: .body)
let size = metrics.scaledValue(for: 17.0)
If the device is set to the .large dynamic type setting, the identity value is returned (size == 17.0). If you then downscale the device’s dynamic type size setting to .medium, one might expect the returned value to be 16.0. After all, the default system .body font size at .large is exactly 17.0, and the default .body font size at .medium is exactly 16.0. But instead, this is what happens:
// current dynamic type size setting is .medium...
let metrics = UIFontMetrics(forTextStyle: .body)
let size = metrics.scaledValue(for: 17.0)
// size == 16.333...
The divergence is even more pronounced the further up/down the dynamic type size range one goes:

The red text in each pairing the above is the system default .body font, and the black text is a system body font obtained using a ScaledMetric:
@ScaledMetric(relativeTo: .body) var scaled = 17.0
var body: some View {
Text("Quick, brown fox.")
.foregroundStyle(.red)
.font(.body)
.overlay {
Text("Quick, brown fox.")
.foregroundStyle(.black)
.font(.system(size: scaled))
}
}
So if you need to scale a bit of UI in exact proportion to the .body font size, avoid using ScaledMetric/UIFontMetrics scaling APIs and instead directly obtain the pointSize from a system body font and use that value instead:
UIFont.preferredFont(
forTextStyle: .body,
compatibleWith: traitCollection
).pointSize

(EDITED: An earlier version of this post included an erroneous assumption that has been living rent-free in my brain for years. Thanks to Matthias for the clarification.)